Seite 1 von 2
Korrelation von unterschiedlichen Datensätzen

Verfasst:
Do 29. Sep 2016, 15:26von G21G
Hallo
Ich habe 2 xy Kurven (Konzentration vs. MFR), mit unterschiedlichen Werten sowohl für x als auch y. z.B.
Set1 = [2.68,4.32,6.92,8.38,9.51,9.54;10.3,18.6,40,58,49,50];
Set2 = [1.01,1.01,1.2,1.3,2.19,3.28,4.74,8.84,8.87,9.35;1.55,1.83,1.79,2.4,2.51,6.5,12.5,27.2,49,45,70]
Ich möchte nun sehen ob sich diese beiden Datensätze signifikant voneinander unterscheiden bzw. ob sie korrelieren. Beide können gut mittels einer Potenzregression beschrieben werden (R² > 0.95). Optisch unterscheiden sich diese beiden kaum.
Ist es zulässig bzw. eine Möglichkeit die fehlenden Datenpunkte zu interpolieren, um dann die Korrelationskoeffizienten berechnen zu können ?
Welche Methode würdet ihr vorschlagen ?
Danke
MfG Günter
Re: Korrelation von unterschiedlichen Datensätzen
Verfasst:
Do 29. Sep 2016, 16:02von bele
G21G hat geschrieben:Ich möchte nun sehen ob sich diese beiden Datensätze signifikant voneinander unterscheiden bzw. ob sie korrelieren.
Sich unterscheiden und miteinander korrellieren sind zwei ganz verschiedene Fragen. Zunächst ist mir aber unklar, was Du unter einem Datensatz verstehst. Ist ein "Set" ein Datensatz oder sind die beiden durch Semikolon in einem Set getrennten Zahlenfolgen ein Datensatz?
Ist es zulässig bzw. eine Möglichkeit die fehlenden Datenpunkte zu interpolieren, um dann die Korrelationskoeffizienten berechnen zu können ?
Korrelationskoeffizienten berechnet man normalerweise mit den tatsächlich vorhandenen Daten, aber es kann sein, dass ich die Frage ganz falsch verstehe (siehe oben).
Welche Methode würdet ihr vorschlagen ?
Eine vernünftige Beschreibung des zugrundeliegenden Problems, der Natur der Daten und der zu beantwortenden Fragestellung wäre methodisch nicht verkehrt.
LG,
Bernhard
Re: Korrelation von unterschiedlichen Datensätzen
Verfasst:
Do 29. Sep 2016, 16:45von G21G
Hallo
Es wurden 2 verschiedene Chargen desselben Produkts hergestellt (Datensatz 1 und 2). Während des Prozesses werden Proben entnommen, die Konzentration bestimmt (= X-Wert) und daraufhin eine Messung (MFI) durchgeführt (= Y-Wert) => wobei im Regelfall eine höhere Konzentration zu einem höheren MFI führt. Die Wertepaare von Datensatz 1 & 2 weisen unterschiedliche Konzentrationen (X-Werte) auf, soll heißen ich habe keine Messwerte (y) von Datensatz 2 für die Konzentrationen (x) von Datensatz 1 und visa versa. Wobei ich dazu sagen muss, dass die Anzahl des Messungen limitiert ist (max. 13 pro Charge). Nun ist die Frage unterscheiden sich diese beiden Chargen, basierend auf den vorhandenen Wertepaaren, signifikant.
Set ist ein Datensatz, das Semikolon trennt die x von den y Werten
MfG Günter
Re: Korrelation von unterschiedlichen Datensätzen
Verfasst:
Do 29. Sep 2016, 21:32von bele
Kann man irgendwelche Annahmen zum Zusammenhang zwischen x und y treffen, z.B., dass sie auf einer Geraden liegen oder dass sie sich in einem Kreis um einen gemeinsamen Mittelpunkt verteilen oder irgendetwas anderes, womit man Deinen Begriff des Korrelierens etwas präziser fassen könnte?
LG,
Bernhard
Re: Korrelation von unterschiedlichen Datensätzen
Verfasst:
Fr 30. Sep 2016, 10:43von G21G
Hallo Bernhard
Was man sicher sagen kann ist, dass eine höhere Konzentration zu einem höheren MFI Wert führt. Dieser Verlauf kann gut mit einer Potenzregression beschrieben werden (R² > 0.95), wobei natürlich nicht alle Punkte auf der Ausgleichskurve liegen.
Interessiert bin ich, ob es möglich ist eine Aussage zu treffen ob sich Charge 1 (Datensatz 1) merklich/signifikant von Charge 2 (Datensatz 2) unterscheidet.
MfG Günter
Re: Korrelation von unterschiedlichen Datensätzen
Verfasst:
Fr 30. Sep 2016, 13:36von bele
Von der wievielten Potenz sprechen wir denn? Bei nur 13 Wertepaaren lassen sich halt nur begrenzt viele Koeffizienten bestimmen bzw mit genügend vielen Potenzen lassen sich wenige Punkte immer schön annähern.
Wenn ich das richtig verstehe, dann willst Du zeigen, dass diese 13 Punkte und jene 13 Punkte auf der gleichen Linie liegen, die einer quadratischen oder kubischen oder höherordrigen polynomen Funktino folgt?
Re: Korrelation von unterschiedlichen Datensätzen
Verfasst:
Mo 3. Okt 2016, 13:14von G21G
Hallo
Von der wievielten Potenz sprechen wir denn? Bei nur 13 Wertepaaren lassen sich halt nur begrenzt viele Koeffizienten bestimmen bzw mit genügend vielen Potenzen lassen sich wenige Punkte immer schön annähern.
Potenz der Ausgleichskurve ist ~1.6-2.4
Wenn ich das richtig verstehe, dann willst Du zeigen, dass diese 13 Punkte und jene 13 Punkte auf der gleichen Linie liegen, die einer quadratischen oder kubischen oder höherordrigen polynomen Funktino folgt?
Genau, bzw abschätzen ob sie sich signifikant unterscheiden
Meine Daten sind:
Dataset 1:
x,y
2.67948723,10.3
4.32144165,18.6
6.91549492,40
8.38325500,49
9.50781250,50
9.54225159,58
10.3186760,80
10.3332672,85
10.3398771,87
10.3526955,92
10.4671631,93
10.8136120,93
10.8360834,96
Datset 2:
x,y
1.00513458,1.55
1.00921738,1.79
1.01075900,1.83
1.20497000,2.40
1.30093348,2.51
2.19338202,6.50
3.27699137,12.5
3.28192520,12.5
4.73765564,27.2
8.83782482,45
8.87116241,49
9.34879780,70
9.34949589,74
Re: Korrelation von unterschiedlichen Datensätzen
Verfasst:
Mi 12. Okt 2016, 08:30von G21G
Hallo Bernhard
Ich habe von dir leider nichts mehr gehört, heißt das es ist nicht möglich ?
MfG Günter
Re: Korrelation von unterschiedlichen Datensätzen
Verfasst:
Mi 12. Okt 2016, 09:59von bele
Hallo,
nein, das heißt nur, dass ich beruflich, privat und gesundheitlich wichtigeres zu tun hatte, als im Forum zu posten. Sorry, ich hatte das mit der Potenzfunktion irgendwie falsch verstanden.
Deine Potenzfunktion folgt irgendwie der Gleichung
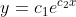
Wenn Du davon auf beiden Seiten den natürlich Logarithmus nimmst, dann wird daraus
 = log(c_1) + c_2 x)
Das wiederum ist eine Geradengleichung. Du kannst also Deine x-Werte und die Logarithmen Deiner y-Werte in eine lineare Regression stecken und erhälst aus der Regression die Schätzwerte für
)
und für
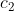
. Darüber hinaus erhälst Du die Standardfehler für beide Parameter und kannst dann sagen, ob sich
oder
bei beiden Regressionen die Konfidenzintervalle für beide Parameter überlappen oder nicht.
LG,
Bernhard
Re: Korrelation von unterschiedlichen Datensätzen
Verfasst:
Mi 12. Okt 2016, 10:21von bele
In R könnte das so aussehen:
- Code: Alles auswählen
ds1 <- data.frame(
x = c(
2.67948723,
4.32144165,
6.91549492,
8.38325500,
9.50781250,
9.54225159,
10.3186760,
10.3332672,
10.3398771,
10.3526955,
10.4671631,
10.8136120,
10.8360834
),
y = c(10.3
,18.6
,40
,49
,50
,58
,80
,85
,87
,92
,93
,93
,96)
)
ds2 <- data.frame(
x = c(
1.00513458,
1.00921738,
1.01075900,
1.20497000,
1.30093348,
2.19338202,
3.27699137,
3.28192520,
4.73765564,
8.83782482,
8.87116241,
9.34879780,
9.34949589
),
y = c(1.55
,1.79
,1.83
,2.40
,2.51
,6.50
,12.5
,12.5
,27.2
,45
,49
,70
,74)
)
model1 <- lm(log(y)~x, data = ds1)
model2 <- lm(log(y)~x, data = ds2)
summary(model1)
summary(model2)
mit folgenden Ergebnissen:
- Code: Alles auswählen
> summary(model1)
Call:
lm(formula = log(y) ~ x, data = ds1)
Residuals:
Min 1Q Median 3Q Max
-0.28330 -0.02442 0.02319 0.07821 0.16852
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.71978 0.12442 13.82 2.69e-08 ***
x 0.26037 0.01355 19.22 8.19e-10 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.1232 on 11 degrees of freedom
Multiple R-squared: 0.9711, Adjusted R-squared: 0.9685
F-statistic: 369.4 on 1 and 11 DF, p-value: 8.187e-10
> summary(model2)
Call:
lm(formula = log(y) ~ x, data = ds2)
Residuals:
Min 1Q Median 3Q Max
-0.5416 -0.3461 -0.1794 0.4106 0.8114
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.57272 0.21123 2.711 0.0202 *
x 0.40508 0.03874 10.458 4.72e-07 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.4748 on 11 degrees of freedom
Multiple R-squared: 0.9086, Adjusted R-squared: 0.9003
F-statistic: 109.4 on 1 and 11 DF, p-value: 4.719e-07
Der Schätzung für
liegt im Dataset 1 also bei 1,720 plusminus 1,96 * 0,124 und im Dataset 2 bei 0,572 plusminus 1,96 * 0.211. Damit wäre dieser Faktor schon mal klar signifikant unterschiedlich in diesem Modell. Frag mich jetzt bitte nicht, wie man das in Excel nachkocht.
LG,
Bernhard