
Hallo,
für meine anstehende Bacherlorarbeit benötige ich etwas Hilfe.
Statistik hatten wird damals im 1. Semester und war ein "Statistics 101" Kurs. Ein Blick in die alten Unterlagen hilft mir bei meinem Problem nicht weiter.
Problemstellung (abgeändert):
Beim Arbeitsamt wird unter den Mitarbeitern eine anonymer und freiwilliger Test durchgeführt, wie lange sie für die Bearbeitung einer bestimmten Kategorie von Personaldaten benötigen. Sinn der Befragung ist, die zeitliche Dauer des Vorgangs zu erfassen und für die zukünftige Personalbedarfsplanung zu nutzen. Dabei ist zu beachten, dass die Bearbeitung der Personaldaten zum Teil aufgrund Dritter zu einer erheblichen Verlängerung des Bearbeitungszeitraums um den Faktor 4-5 kommen kann.
Eine simple Ermittlung des Mittelwerts als alleinige zeitliche Basis zukünftiger Planungen ist natürlich unzureichend und realitätsfern. Auf die Idee ist man früher schon gekommen und kläglich gescheitert. Durch den Einfluss Dritter in den Zeitbedarf, ist die Personalplanung eine Schätzung und kann nicht wie bei einer Fließbandproduktion exakt errechnet werden. Als Idee schweben mir zeitliche Puffer zusätzlich zum im Schnitt ermittelten Zeitaufwand vor. Ergänzend ist zu erwähnen, dass die Datensätze gem. K-S Test parametrisch sind.
Diese Puffer würde ich gerne dynamisch anlegen. Angenommen es erfolgt eine stetige Erfassung der Bearbeitungszeiten, dann soll sich auch dieser Puffer mit der wachsenden Datenmenge anpassen. Dabei soll der Puffer so weit wie möglich ausgeschöpft werden, aus Verrechnungsgründen sollte aber nicht überschritten werden.
Beispiel:
Datensatz 1:
Bearbeitungszeit Mittelwert: 22,7min
95% Konfidenzintervall: 17,6-27,9min
auf 5% getrimmter Wert: 21,4min
Median: 16,5
Standardabweichung 13,7min
Datensatz 1+2(neue Daten):
Bearbeitungszeit Mittelwert: 25,3min
95% Konfidenzintervall: 21,3-29,3min
auf 5% getrimmter Wert: 24,4min
Median: 17
Standardabweichung 15min
Datensatz 1+2+3
Bearbeitungszeit Mittelwert: 22,4min
95% Konfidenzintervall: 19,2-25,6min
auf 5% getrimmter Wert: 21,2min
Median: 16
Standardabweichung 13,9min
Da meine Statistik Kenntnisse nun recht begrenzt sind, meine Frage an die Experten. Gibt es vielleicht schon sinnvolle Methoden in der Richtung, oder habt ihr Ideen/Anregungen, wie diese Problemstellung weiter angegangen werden kann?
Arbeiten mit wachsenden Datensätzen für zukünft. Schätzungen
Thema bewerten:  • 7 Beiträge
• Seite 1 von 1
• 7 Beiträge
• Seite 1 von 1
Arbeiten mit wachsenden Datensätzen für zukünft. Schätzungen
![]() von WingCand » Di 11. Mär 2014, 17:08
von WingCand » Di 11. Mär 2014, 17:08
- WingCand
- Grünschnabel

- Beiträge: 3
- Registriert: Di 11. Mär 2014, 14:34
- Danke gegeben: 0
- Danke bekommen: 0 mal in 0 Post
Re: Arbeiten mit wachsenden Datensätzen für zukünft. Schätzu
![]() von PonderStibbons » Di 11. Mär 2014, 17:35
von PonderStibbons » Di 11. Mär 2014, 17:35
Das Thema Deiner Studie fällt nicht in meinen Kompetenzbereich,
aber ein paar Anmerkungen zur Darstellung:
Ist es nun ein Test, eine Befragung, eine Beobachtungsstudie?
Oder ist das egal?
Was heißt "aufgrund Dritter", das ist nicht so recht klar. Und wie oft
kommt es zu solchen Verzögerungen?
Warum? Der Mittelwert bleibt der Schätzer mit der
geringsten Summe der Abweichungsquadrate.
In welcher Hinsicht, woran ist es gescheitert?
Und was bedeutet in dem Zusammenhang kläglich,
wie stark waren denn die Abweichungen zwischen Planungen
und tatsächlichem Bedarf?
Sicher. Aber über N Vorgänge hinweg sollten sich normalerweise
auch die Störungen berücksichtigen lassen. Oder geht es um
Kurzzeit-Planung mit nur wenigen Vorgängen im Planungszeitraum?
Datensätze können nicht parametrisch sein (nur Tests können dies sein).
Falls Du damit meinst, Du hast Daten, bei welchen es dem Kolmogorov-
Smirnov-Test nicht gelungen ist, die Normalverteilungsannahme
zurückzuweisen -- das kann bei Zeitangaben nur an einer zu kleinen
Stichprobe liegen, Zeitbedarf ist praktisch nie normalverteilt.
Zudem widerspricht es auch Deiner Ausage, dass es da markante
Ausreißer gibt. Und schließlich zeigt ja auch Deine Desriptivstatistk einen
großen Unterschied zwischen Mittelwert und Median, d.h. es
ist eine schiefe und/oder mit Ausreißern versehene Verteilung.
Wie gesagt, es ist nicht mein Beritt, aber es scheint momentan etwas
schwierig, Dein konkretes Problem und Ziel nachzuvollziehen.
Mit freundlichen Grüßen
P.
aber ein paar Anmerkungen zur Darstellung:
Beim Arbeitsamt wird unter den Mitarbeitern eine anonymer und freiwilliger Test durchgeführt, wie lange sie für die Bearbeitung einer bestimmten Kategorie von Personaldaten benötigen. Sinn der Befragung ist,
Ist es nun ein Test, eine Befragung, eine Beobachtungsstudie?
Oder ist das egal?
die zeitliche Dauer des Vorgangs zu erfassen und für die zukünftige Personalbedarfsplanung zu nutzen. Dabei ist zu beachten, dass die Bearbeitung der Personaldaten zum Teil aufgrund Dritter zu einer erheblichen Verlängerung des Bearbeitungszeitraums um den Faktor 4-5 kommen kann.
Was heißt "aufgrund Dritter", das ist nicht so recht klar. Und wie oft
kommt es zu solchen Verzögerungen?
Eine simple Ermittlung des Mittelwerts als alleinige zeitliche Basis zukünftiger Planungen ist natürlich unzureichend und realitätsfern.
Warum? Der Mittelwert bleibt der Schätzer mit der
geringsten Summe der Abweichungsquadrate.
Auf die Idee ist man früher schon gekommen und kläglich gescheitert.
In welcher Hinsicht, woran ist es gescheitert?
Und was bedeutet in dem Zusammenhang kläglich,
wie stark waren denn die Abweichungen zwischen Planungen
und tatsächlichem Bedarf?
Durch den Einfluss Dritter in den Zeitbedarf, ist die Personalplanung eine Schätzung und kann nicht wie bei einer Fließbandproduktion exakt errechnet werden
Sicher. Aber über N Vorgänge hinweg sollten sich normalerweise
auch die Störungen berücksichtigen lassen. Oder geht es um
Kurzzeit-Planung mit nur wenigen Vorgängen im Planungszeitraum?
Als Idee schweben mir zeitliche Puffer zusätzlich zum im Schnitt ermittelten Zeitaufwand vor. Ergänzend ist zu erwähnen, dass die Datensätze gem. K-S Test parametrisch sind.
Datensätze können nicht parametrisch sein (nur Tests können dies sein).
Falls Du damit meinst, Du hast Daten, bei welchen es dem Kolmogorov-
Smirnov-Test nicht gelungen ist, die Normalverteilungsannahme
zurückzuweisen -- das kann bei Zeitangaben nur an einer zu kleinen
Stichprobe liegen, Zeitbedarf ist praktisch nie normalverteilt.
Zudem widerspricht es auch Deiner Ausage, dass es da markante
Ausreißer gibt. Und schließlich zeigt ja auch Deine Desriptivstatistk einen
großen Unterschied zwischen Mittelwert und Median, d.h. es
ist eine schiefe und/oder mit Ausreißern versehene Verteilung.
Diese Puffer würde ich gerne dynamisch anlegen.
Wie gesagt, es ist nicht mein Beritt, aber es scheint momentan etwas
schwierig, Dein konkretes Problem und Ziel nachzuvollziehen.
Mit freundlichen Grüßen
P.
- PonderStibbons
- Foren-Unterstützer

- Beiträge: 11372
- Registriert: Sa 4. Jun 2011, 15:04
- Wohnort: Ruhrgebiet
- Danke gegeben: 51
- Danke bekommen: 2504 mal in 2488 Posts
Re: Arbeiten mit wachsenden Datensätzen für zukünft. Schätzu
![]() von WingCand » Di 11. Mär 2014, 18:27
von WingCand » Di 11. Mär 2014, 18:27
Vielen Dank für deine schnelle Antwort.
Es hilft mir schon einmal ungemein, dass du mir erklärt hast, warum die Zeitwerte nicht parametrisch sind. Das war mir auch suspekt, doch nach dem K-S Test habe ich das anscheinend etwas voreilig akzeptiert.
Es handelt sich hier um eine Beobachtungsstudie.
Die Mitarbeiter wurden zuerst gefragt, wie lange sie denn ungefähr für Tätigkeit A benötigten. Die Aussagen waren sehr unterschiedlich. Aus dem Grund hat man den Mitarbeitern angeboten, freiwillig die benötigten Zeiträume für diese Tätigkeiten.
Einflüsse Dritter sind z.B. Telefonate zur Recherche von fehlenden bzw Bestätigung von zweifelhaften Daten, oder eine Unterbrechung eines Kollegen mit Fragen etc in diesem Bearbeitungszeitraum. So sehr möchte aber nicht ins Detail gegangen werden.
Problematisch ist der Mittelwert in dem Bezug auf den tatsächlich relativ kurzen Zeitraum dieser Tätigkeit. Dieser Zeitraum ist auch nicht periodisch, da sich der Umfang nur grob ähnelt. Es werden nicht genug Daten zusammengetragen, um genaue Ergebnisse zu erzielen. Es gab früher immer teils massive Abweichungen. Das kann auch an der Ermittlung des späteren verwendeten Standardwertes liegen. Vielleicht wurden die Randbedingungen des tägliches Arbeitsumfeldes nicht berücksichtigt. Dazu liegen mir jedoch keine Informationen vor. Tatsache ist, dass es immer wieder zu unvorhergesehenen Verlängerungen der Bearbeitungszeit kommt. Aus diesem Grund würde ich das Problem gern mit Puffern angehen. Es ist nicht das Ziel der Arbeit ein fertiges Prognose-System zu entwickeln, doch würde ich gern einen Lösungsvorschlag in dieser Richtung unterbreiten.
Es hilft mir schon einmal ungemein, dass du mir erklärt hast, warum die Zeitwerte nicht parametrisch sind. Das war mir auch suspekt, doch nach dem K-S Test habe ich das anscheinend etwas voreilig akzeptiert.
Es handelt sich hier um eine Beobachtungsstudie.
Die Mitarbeiter wurden zuerst gefragt, wie lange sie denn ungefähr für Tätigkeit A benötigten. Die Aussagen waren sehr unterschiedlich. Aus dem Grund hat man den Mitarbeitern angeboten, freiwillig die benötigten Zeiträume für diese Tätigkeiten.
Einflüsse Dritter sind z.B. Telefonate zur Recherche von fehlenden bzw Bestätigung von zweifelhaften Daten, oder eine Unterbrechung eines Kollegen mit Fragen etc in diesem Bearbeitungszeitraum. So sehr möchte aber nicht ins Detail gegangen werden.
Problematisch ist der Mittelwert in dem Bezug auf den tatsächlich relativ kurzen Zeitraum dieser Tätigkeit. Dieser Zeitraum ist auch nicht periodisch, da sich der Umfang nur grob ähnelt. Es werden nicht genug Daten zusammengetragen, um genaue Ergebnisse zu erzielen. Es gab früher immer teils massive Abweichungen. Das kann auch an der Ermittlung des späteren verwendeten Standardwertes liegen. Vielleicht wurden die Randbedingungen des tägliches Arbeitsumfeldes nicht berücksichtigt. Dazu liegen mir jedoch keine Informationen vor. Tatsache ist, dass es immer wieder zu unvorhergesehenen Verlängerungen der Bearbeitungszeit kommt. Aus diesem Grund würde ich das Problem gern mit Puffern angehen. Es ist nicht das Ziel der Arbeit ein fertiges Prognose-System zu entwickeln, doch würde ich gern einen Lösungsvorschlag in dieser Richtung unterbreiten.
- WingCand
- Grünschnabel
- Beiträge: 3
- Registriert: Di 11. Mär 2014, 14:34
- Danke gegeben: 0
- Danke bekommen: 0 mal in 0 Post
Re: Arbeiten mit wachsenden Datensätzen für zukünft. Schätzu
![]() von PonderStibbons » Di 11. Mär 2014, 18:41
von PonderStibbons » Di 11. Mär 2014, 18:41
Es hilft mir schon einmal ungemein, dass du mir erklärt hast, warum die Zeitwerte nicht parametrisch sind.
Da solltest Du Dich nochmal einlesen. Werte oder Daten können
weder parametrisch noch non-parametrisch sein. Das betrifft sie
nicht. Nur Tests können parametrisch oder non-parametrisch sein.
Problematisch ist der Mittelwert in dem Bezug auf den tatsächlich relativ kurzen Zeitraum dieser Tätigkeit.
Im Median etwas über eine Viertelstunde. Ist das denn wirklich
so kurz? Und außerdem ändert es doch nicht sehr viel an dem
Zeitbedarf für eine Arbeit, wenn sie unterbrochen wird für
andere Tätigkeiten. Allenfalls die Zeitspanne zwischen Beginn
und Ende der Erledigung der Aufgabe ändert sich. Und wenn
Störungen so häufig auftreten wie angedeutet, kann man sie
einrechnen. Aber die Aufgabenstellung wird mir da leider nicht
transparent; "für die zukünftige Personalbedarfsplanung nutzen"
ist ja nun sehr diffus.
Tatsache ist, dass es immer wieder zu unvorhergesehenen Verlängerungen der Bearbeitungszeit kommt. Aus diesem Grund würde ich das Problem gern mit Puffern angehen. Es ist nicht das Ziel der Arbeit ein fertiges Prognose-System zu entwickeln, doch würde ich gern einen Lösungsvorschlag in dieser Richtung unterbreiten.
Wie gesagt, das Thema ist mir zu fern, als dass ich mir auf Anhieb
etwas Konkretes darunter vorstellen könnte.
Mit freundlichen Grüßen
P.
- PonderStibbons
- Foren-Unterstützer
- Beiträge: 11372
- Registriert: Sa 4. Jun 2011, 15:04
- Wohnort: Ruhrgebiet
- Danke gegeben: 51
- Danke bekommen: 2504 mal in 2488 Posts
Re: Arbeiten mit wachsenden Datensätzen für zukünft. Schätzu
![]() von bele » Do 20. Mär 2014, 17:48
von bele » Do 20. Mär 2014, 17:48
Hallo,
Ich verstehe das bisher so: Ein Mitarbeiter arbeitet am Tag 8 Stunden. Darin soll er n Akten bearbeiten und wird m Mal gestört. Eine Akte bearbeiten dauert , eine Störung dauert
, eine Störung dauert  . Wieviele Akten n kann ich ihm zumuten, damit in 99% der Fälle gilt:
. Wieviele Akten n kann ich ihm zumuten, damit in 99% der Fälle gilt:

Wobei und und m jeweils keine Konstanten sind sondern Zufallszahlen, die einer noch zu ermittelnden Verteilung (sagen wir, einer Negativen Binomialverteilung oder loglinear für die t und Poisson für m?) entnommen sind.
Habe ich das soweit richtig wiedergegeben?
Das klingt so, als könnte man da recht einfach eine Simulation draus machen oder vielleicht so gar die Werte in WinBUGS berechnen lassen. Du hast Informationen zur Verteilung von. Hast Du auch Informationen zur Verteilung von und m?
LG,
Bernhard
PS: Falls man sich nicht auf eine bestimmte Verteilung einigen kann könnte man aus beobachteten Zeiten auch bootstrappen...
Ich verstehe das bisher so: Ein Mitarbeiter arbeitet am Tag 8 Stunden. Darin soll er n Akten bearbeiten und wird m Mal gestört. Eine Akte bearbeiten dauert
Wobei
Habe ich das soweit richtig wiedergegeben?
Das klingt so, als könnte man da recht einfach eine Simulation draus machen oder vielleicht so gar die Werte in WinBUGS berechnen lassen. Du hast Informationen zur Verteilung von
LG,
Bernhard
PS: Falls man sich nicht auf eine bestimmte Verteilung einigen kann könnte man aus beobachteten Zeiten auch bootstrappen...
----
`Oh, you can't help that,' said the Cat: `we're all mad here. I'm mad. You're mad.'
`How do you know I'm mad?' said Alice.
`You must be,' said the Cat, `or you wouldn't have come here.'
(Lewis Carol, Alice in Wonderland)
`Oh, you can't help that,' said the Cat: `we're all mad here. I'm mad. You're mad.'
`How do you know I'm mad?' said Alice.
`You must be,' said the Cat, `or you wouldn't have come here.'
(Lewis Carol, Alice in Wonderland)
- bele
- Schlaflos in Seattle

- Beiträge: 5944
- Registriert: Do 2. Jun 2011, 23:16
- Danke gegeben: 16
- Danke bekommen: 1405 mal in 1391 Posts
Re: Arbeiten mit wachsenden Datensätzen für zukünft. Schätzu
![]() von WingCand » Sa 22. Mär 2014, 19:23
von WingCand » Sa 22. Mär 2014, 19:23
Danke für deine Antwort und die PN. 
Vom Prinzip her hast du es ungefähr erfasst, ja. t(störung) und m liegen allerdings nicht einzeln vor. Ich rede im Moment mit dem Betriebsrat über eine detailliertere Erhebung, aber der will das aus verständlichen Gründen nur sehr ungern. Bis es eine endgültige Entscheidung gibt, muss ich sehen, ob es eine Möglichkeit gibt die zeitliche Störung aus den bisher erfassten Daten wenigsten ungefähr abzuschätzen.
Vom Prinzip her hast du es ungefähr erfasst, ja. t(störung) und m liegen allerdings nicht einzeln vor. Ich rede im Moment mit dem Betriebsrat über eine detailliertere Erhebung, aber der will das aus verständlichen Gründen nur sehr ungern. Bis es eine endgültige Entscheidung gibt, muss ich sehen, ob es eine Möglichkeit gibt die zeitliche Störung aus den bisher erfassten Daten wenigsten ungefähr abzuschätzen.
- WingCand
- Grünschnabel
- Beiträge: 3
- Registriert: Di 11. Mär 2014, 14:34
- Danke gegeben: 0
- Danke bekommen: 0 mal in 0 Post
Re: Arbeiten mit wachsenden Datensätzen für zukünft. Schätzu
![]() von bele » Sa 22. Mär 2014, 20:09
von bele » Sa 22. Mär 2014, 20:09
Ok, liegen denn und 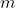 als Produkt vor? Dank könnte man das ja als festen Term nutzen. Anders herum, könnte man die Formel umstellen und
als Produkt vor? Dank könnte man das ja als festen Term nutzen. Anders herum, könnte man die Formel umstellen und  schätzen, wenn man
schätzen, wenn man 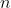 kennen würde, aber das läuft dann wahrscheinlich in die falsche Richtung für Dich. Sind denn andere Zahlen bekannt? Ich meine, es muss doch auch dem Betriebsrat klar sein, dass man nur aus der Dauer der Bearbeitung einer Akte nicht darauf folgern kann, wie lange Akte Bearbeiten plus etwas anderes dauert!?
kennen würde, aber das läuft dann wahrscheinlich in die falsche Richtung für Dich. Sind denn andere Zahlen bekannt? Ich meine, es muss doch auch dem Betriebsrat klar sein, dass man nur aus der Dauer der Bearbeitung einer Akte nicht darauf folgern kann, wie lange Akte Bearbeiten plus etwas anderes dauert!?
LG,
Bernhard
LG,
Bernhard
----
`Oh, you can't help that,' said the Cat: `we're all mad here. I'm mad. You're mad.'
`How do you know I'm mad?' said Alice.
`You must be,' said the Cat, `or you wouldn't have come here.'
(Lewis Carol, Alice in Wonderland)
`Oh, you can't help that,' said the Cat: `we're all mad here. I'm mad. You're mad.'
`How do you know I'm mad?' said Alice.
`You must be,' said the Cat, `or you wouldn't have come here.'
(Lewis Carol, Alice in Wonderland)
- bele
- Schlaflos in Seattle
- Beiträge: 5944
- Registriert: Do 2. Jun 2011, 23:16
- Danke gegeben: 16
- Danke bekommen: 1405 mal in 1391 Posts
Thema bewerten: • 7 Beiträge
• Seite 1 von 1
Wer ist online?
Mitglieder in diesem Forum: Bing [Bot], Google [Bot] und 2 Gäste