
Hallo zusammen,
ich mache eine Rolling Beta Regression als Expanding Window.
Genauer gesagt nehme ich Wachstumsraten aus einer Zeitreihe und regressiere Sie auf die Wachstumsraten einer anderen Zeitreihe.
Ich schätze keine Konstante mit.(Frage 1. !)
Die erste Regression mache ich mit 30 Beobachtungen, (Es sind Makrodaten, deswegen so wenig) die nächste mit 31, 32, 33, ...64
Dann schaue ich mir die Entwicklung meines Betas und des P-Wert des Betas an, um zu überprüfen ob es über die Zeitachse starke Schwankungen beider Werte gibt.
Jetzt zu meinen Fragen:
1. Darf ich einen T-Test machen, wenn ich keine Konstante mitschätze?
2. Wird der P-Wert "automatisch" besser mit mehr Beobachtungen? (Es steht ja N im Zähler und N-1 im Nenner [Standartabweichung], sollte man da irgendwie einen Strafterm oder so hinzufügen?)
Vielen Dank
Lombs
Vergleichbarkeit von T-Tests verschieden großer Stichproben
Thema bewerten:  • 5 Beiträge
• Seite 1 von 1
• 5 Beiträge
• Seite 1 von 1
Vergleichbarkeit von T-Tests verschieden großer Stichproben
![]() von lombs » Mi 10. Apr 2013, 10:11
von lombs » Mi 10. Apr 2013, 10:11
- lombs
- Grünschnabel

- Beiträge: 5
- Registriert: Mi 10. Apr 2013, 09:52
- Danke gegeben: 0
- Danke bekommen: 0 mal in 0 Post
Re: Vergleichbarkeit von T-Tests verschieden großer Stichpro
![]() von aziz » Mi 10. Apr 2013, 14:21
von aziz » Mi 10. Apr 2013, 14:21
Hallo,
Ich wüsste nicht, was dagegen sprechen sollte.
Bei jedem statistischen Test, wird der p-Wert mit höheren Beobachtungsumfang kleiner. D. h. je höher der Stichprobenumfang, desto größer ist die Chance, dass die Nullhypothese (Hier: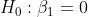 ) verworfen wird. Dies hängt damit zusammen, dass für sehr große Stichprobenumfänge die Tests schon auf kleinste Abweichungen (innerhalb der Stichprobe) von der Nullhypothese reagieren (Auch, wenn der Unterschied nicht von einer praktischen Relevanz geprägt ist). Dies sollte bei dir nicht der Fall sein.
) verworfen wird. Dies hängt damit zusammen, dass für sehr große Stichprobenumfänge die Tests schon auf kleinste Abweichungen (innerhalb der Stichprobe) von der Nullhypothese reagieren (Auch, wenn der Unterschied nicht von einer praktischen Relevanz geprägt ist). Dies sollte bei dir nicht der Fall sein.
Wo?
Die 30 Beobachtungen aus der ersten Regression sind aber nicht in den anderen Stichproben enthalten, oder? Falls ja, so könnte dies in einem multiplen Testproblem resultieren.
Gruß
A
lombs hat geschrieben:1. Darf ich einen T-Test machen, wenn ich keine Konstante mitschätze?
Ich wüsste nicht, was dagegen sprechen sollte.
lombs hat geschrieben:2. Wird der P-Wert "automatisch" besser mit mehr Beobachtungen? (Es steht ja N im Zähler und N-1 im Nenner [Standartabweichung], sollte man da irgendwie einen Strafterm oder so hinzufügen?)
Bei jedem statistischen Test, wird der p-Wert mit höheren Beobachtungsumfang kleiner. D. h. je höher der Stichprobenumfang, desto größer ist die Chance, dass die Nullhypothese (Hier:
lombs hat geschrieben:(Es steht ja N im Zähler und N-1 im Nenner [Standartabweichung], sollte man da irgendwie einen Strafterm oder so hinzufügen?)
Wo?
lombs hat geschrieben:Die erste Regression mache ich mit 30 Beobachtungen, (Es sind Makrodaten, deswegen so wenig) die nächste mit 31, 32, 33, ...64
Dann schaue ich mir die Entwicklung meines Betas und des P-Wert des Betas an, um zu überprüfen ob es über die Zeitachse starke Schwankungen beider Werte gibt.
Die 30 Beobachtungen aus der ersten Regression sind aber nicht in den anderen Stichproben enthalten, oder? Falls ja, so könnte dies in einem multiplen Testproblem resultieren.
Gruß
A
- aziz
- Danke gegeben:
- Danke bekommen: mal in Post
Re: Vergleichbarkeit von T-Tests verschieden großer Stichpro
![]() von lombs » Do 11. Apr 2013, 11:37
von lombs » Do 11. Apr 2013, 11:37
lombs hat geschrieben:1. Darf ich einen T-Test machen, wenn ich keine Konstante mitschätze?
Ich wüsste nicht, was dagegen sprechen sollte.
Ich auch nicht
lombs hat geschrieben:(Es steht ja N im Zähler und N-1 im Nenner [Standartabweichung], sollte man da irgendwie einen Strafterm oder so hinzufügen?)
Wo?
Die Teststatistik lautet:
n ist also im Zähler und im Nenner, das könnte doch zu Problemen führen?
aziz hat geschrieben: lombs hat geschrieben:Die erste Regression mache ich mit 30 Beobachtungen, (Es sind Makrodaten, deswegen so wenig) die nächste mit 31, 32, 33, ...64
Dann schaue ich mir die Entwicklung meines Betas und des P-Wert des Betas an, um zu überprüfen ob es über die Zeitachse starke Schwankungen beider Werte gibt.
Die 30 Beobachtungen aus der ersten Regression sind aber nicht in den anderen Stichproben enthalten, oder? Falls ja, so könnte dies in einem multiplen Testproblem resultieren.
Doch, leider habe ich genau das vor, ich will die Parameterstabilität untersuchen. Ich habe 62 Datenpunkte, davon nehme ich zuerst nur 30 schätze das beta und den 31. wert, dann nehme ich den 31, schätze das nächste beta und den nächsten wert.
Am Schluss will ich eine entwicklung des Betas (einigermaßen Stabile entwicklung oder nicht?), des P-Wertes (bleibt mein beta signifikant?) und des Schätzfehlers ( mit 30 beobachtungen die 31. schätzen; mit 31, 32 schätzen usw.) Plotten und damit den untersuchten Zusammenhang auf Robustheit über die Zeitachse hinweg prüfen.
Darf ich das nicht?, vielen Dank
L
- lombs
- Grünschnabel
- Beiträge: 5
- Registriert: Mi 10. Apr 2013, 09:52
- Danke gegeben: 0
- Danke bekommen: 0 mal in 0 Post
Re: Vergleichbarkeit von T-Tests verschieden großer Stichpro
![]() von aziz » Do 11. Apr 2013, 12:11
von aziz » Do 11. Apr 2013, 12:11
lombs hat geschrieben:Die Teststatistik lautet:
n ist also im Zähler und im Nenner, das könnte doch zu Problemen führen?
So, wie du mir die Teststatistik aufgeschrieben hast, ist dass
Gruß
Aziz
- aziz
- Danke gegeben:
- Danke bekommen: mal in Post
Re: Vergleichbarkeit von T-Tests verschieden großer Stichpro
![]() von lombs » Fr 26. Apr 2013, 10:58
von lombs » Fr 26. Apr 2013, 10:58
- lombs
- Grünschnabel
- Beiträge: 5
- Registriert: Mi 10. Apr 2013, 09:52
- Danke gegeben: 0
- Danke bekommen: 0 mal in 0 Post
Thema bewerten: • 5 Beiträge
• Seite 1 von 1
Wer ist online?
Mitglieder in diesem Forum: 0 Mitglieder und 4 Gäste