
Hallo liebe Forengemeinde,
ich bin ganz neu hier und gar nicht sicher, ob ich mit meiner Problemstellung richtig bin.
Ich habe einen umfassenden Datensatz aller Profi-Tennisspieler und zu deren bisherigen Matches.
Nun habe ich z.B. folgende Daten:
Spieler A: Macht Punkt bei eigenem Aufschlag in 80% der Fälle, macht Punkte bei Aufschlag des Gegners in 12% aller Fälle
Spieler B: Macht Punkt bei eigenem Aufschlag in 93% der Fälle, macht Punkt bei Aufschlag des Gegners in 9% aller Fälle
Wenn nun Spieler A gegen Spieler B 20 Punkte spielt (je 10 bei eigenem und 10 bei gegnerischem Aufschlag), welches Ergebnis ist das wahrscheinlichste?
Gibt es einen Weg die gegeneinander stehenden Wahrscheinlichkeiten so zu normieren, dass ich sagen kann wie viele Punkte an wen gehen?
Vielen Dank schonmal für Euer Hirnschmalz und eure Unterstützung
Vorhersage eines Tennismatchs
Thema bewerten:  • 5 Beiträge
• Seite 1 von 1
• 5 Beiträge
• Seite 1 von 1
Vorhersage eines Tennismatchs
![]() von FlyingGoshawk » Do 10. Feb 2022, 14:02
von FlyingGoshawk » Do 10. Feb 2022, 14:02
- FlyingGoshawk
- Grünschnabel

- Beiträge: 2
- Registriert: Do 10. Feb 2022, 13:56
- Danke gegeben: 0
- Danke bekommen: 0 mal in 0 Post
Re: Vorhersage eines Tennismatchs
![]() von strukturmarionette » Do 10. Feb 2022, 23:35
von strukturmarionette » Do 10. Feb 2022, 23:35
Hi,
- du könntest deinen umfassenden Datensatz zunächst in ein für dich überschaubares Datenmaterial strukturieren derart,
dass konkret erkennbar wird, welche Variablen überhaupt allesamt in Dein Analysen eingehen sollen
Gruß
S.
- du könntest deinen umfassenden Datensatz zunächst in ein für dich überschaubares Datenmaterial strukturieren derart,
dass konkret erkennbar wird, welche Variablen überhaupt allesamt in Dein Analysen eingehen sollen
Gruß
S.
- strukturmarionette
- Schlaflos in Seattle

- Beiträge: 4375
- Registriert: Fr 17. Jun 2011, 22:15
- Danke gegeben: 33
- Danke bekommen: 587 mal in 584 Posts
Re: Vorhersage eines Tennismatchs
![]() von bele » Fr 11. Feb 2022, 09:50
von bele » Fr 11. Feb 2022, 09:50
Hallo!
Also wenn vorher gesetzt ist, dass jeder 10 mal selbst aufschlägt, dann reden wir sehr wahrscheinlich nicht über ein Tennismatch. Das ist bestimmt wieder eine dieser Parallelprobleme nach Punkt 8 in nutzung-des-forums-f44/das-musste-mal-gepostet-werden-t6682.html#p31013"] oder es ist eine Hausaufgabe.
Gegen welche Gegner wurde das gemessen, mit den 80% versus 12% aller Fälle für Spieler A? Sind Spieler A und Spieler B an dergleichen Spielergruppe normiert worden oder an unterschiedlichen. Wenn an unterschiedlichen, sind diese Spielergebnisse und die Spielergebnisse der anderen untereinander bekannt oder sind sie nicht bekannt? Oder ist das gar kein Problem aus einer richtigen Aufgabenstellung heraus, sondern eine Hausaufgabe/Studienaufgabe?
Bitte erkläre Dein richtiges Problem mit den korrekten Voraussetzungen, die benutzt werden dürfen.
Wenn es sich um eine Hausaufgabe handelt, darf man dann unterstellen, dass Ihr die logistische Funktion bzw. Logits bereits durchgenommen habt? Für diesen Fall, dass es sich einfach um eine akademische Übung mit der Erlaubnis für entsprechende Vereinfachungen im Modell handelt findest Du die wichtigsten Hinweise, wie dieses Problem angegangen werden kann in diesem Dokument unter "1. Introduction" auf Seite 1: https://cran.r-project.org/web/packages ... yTerry.pdf
LG,
Bernhard
Also wenn vorher gesetzt ist, dass jeder 10 mal selbst aufschlägt, dann reden wir sehr wahrscheinlich nicht über ein Tennismatch. Das ist bestimmt wieder eine dieser Parallelprobleme nach Punkt 8 in nutzung-des-forums-f44/das-musste-mal-gepostet-werden-t6682.html#p31013"] oder es ist eine Hausaufgabe.
Gegen welche Gegner wurde das gemessen, mit den 80% versus 12% aller Fälle für Spieler A? Sind Spieler A und Spieler B an dergleichen Spielergruppe normiert worden oder an unterschiedlichen. Wenn an unterschiedlichen, sind diese Spielergebnisse und die Spielergebnisse der anderen untereinander bekannt oder sind sie nicht bekannt? Oder ist das gar kein Problem aus einer richtigen Aufgabenstellung heraus, sondern eine Hausaufgabe/Studienaufgabe?
Bitte erkläre Dein richtiges Problem mit den korrekten Voraussetzungen, die benutzt werden dürfen.
Wenn es sich um eine Hausaufgabe handelt, darf man dann unterstellen, dass Ihr die logistische Funktion bzw. Logits bereits durchgenommen habt? Für diesen Fall, dass es sich einfach um eine akademische Übung mit der Erlaubnis für entsprechende Vereinfachungen im Modell handelt findest Du die wichtigsten Hinweise, wie dieses Problem angegangen werden kann in diesem Dokument unter "1. Introduction" auf Seite 1: https://cran.r-project.org/web/packages ... yTerry.pdf
LG,
Bernhard
----
`Oh, you can't help that,' said the Cat: `we're all mad here. I'm mad. You're mad.'
`How do you know I'm mad?' said Alice.
`You must be,' said the Cat, `or you wouldn't have come here.'
(Lewis Carol, Alice in Wonderland)
`Oh, you can't help that,' said the Cat: `we're all mad here. I'm mad. You're mad.'
`How do you know I'm mad?' said Alice.
`You must be,' said the Cat, `or you wouldn't have come here.'
(Lewis Carol, Alice in Wonderland)
- bele
- Schlaflos in Seattle
- Beiträge: 5976
- Registriert: Do 2. Jun 2011, 23:16
- Danke gegeben: 16
- Danke bekommen: 1412 mal in 1398 Posts
Re: Vorhersage eines Tennismatchs
![]() von FlyingGoshawk » Fr 11. Feb 2022, 13:19
von FlyingGoshawk » Fr 11. Feb 2022, 13:19
Vielen Dank euch erstmal für die Antworten.
Nein, für Hausaufgaben bin ich definitiv zu alt, ich hatte lediglich versucht das Problem zu vereinfachen weil ich aktuell nur bei diesem Schritt ein Problem habe.
Es geht tatsächlich um das Erstellen eines Modells zur Vorhersage von Tennis Matches und mir liegen echte Daten von allen Profi-Tennisspielern vor.
Dabei gibt es zwei Dimensionen, die für mich von besonderer Bedeutung sind nämlich:
Der durchschnittlich gewonnene Anteil aller Punkte bei eigenem Aufschlag in % (sowohl für die gesamte Karriere des Spielers als auch für die letzten 12 Monate) und
durchschnittlicher Anteil aller gewonnen Punkte bei gegnerischem Aufschlag in % (ebenso Karriere gesamt und nur letzte 12 Monate)
Aus diesen Werten würde ich nun gern eine Vorhersage treffen.
Der Einfachheit halber habe ich dass unten geschildert als die Frage "wie gehen die nächsten 10 Punkte aus?" weil es das für mich gerade schwierigste Teilproblem bei der Sache ist.
Sorry dass euch das jetzt auf die Spur einer Textaufgabe geführt hat. Falls das hilft, ist die viel interessantere Frage natürlich, wie geht das Match aus? Das wird allerdings dann eher durch Simulationen gelöst werden, deshalb der Versuch meiner Vereinfachung des Problems.
Der Datensatz ist bereits strukturiert und welche Daten in die Analyse eingehen sollen auch bereits geklärt. Im Grunde suche ich jetzt nur nach einer Normierungsmöglichkeit um zu definieren, wie viele Spiele und Sätze welcher Spieler gewinnt.
Nachtrag: @bele: Vielen Dank für den Link das schaue ich mir mal genauer an, ich glaube das hilft mir sehr!
Nein, für Hausaufgaben bin ich definitiv zu alt, ich hatte lediglich versucht das Problem zu vereinfachen weil ich aktuell nur bei diesem Schritt ein Problem habe.
Es geht tatsächlich um das Erstellen eines Modells zur Vorhersage von Tennis Matches und mir liegen echte Daten von allen Profi-Tennisspielern vor.
Dabei gibt es zwei Dimensionen, die für mich von besonderer Bedeutung sind nämlich:
Der durchschnittlich gewonnene Anteil aller Punkte bei eigenem Aufschlag in % (sowohl für die gesamte Karriere des Spielers als auch für die letzten 12 Monate) und
durchschnittlicher Anteil aller gewonnen Punkte bei gegnerischem Aufschlag in % (ebenso Karriere gesamt und nur letzte 12 Monate)
Aus diesen Werten würde ich nun gern eine Vorhersage treffen.
Der Einfachheit halber habe ich dass unten geschildert als die Frage "wie gehen die nächsten 10 Punkte aus?" weil es das für mich gerade schwierigste Teilproblem bei der Sache ist.
Sorry dass euch das jetzt auf die Spur einer Textaufgabe geführt hat. Falls das hilft, ist die viel interessantere Frage natürlich, wie geht das Match aus? Das wird allerdings dann eher durch Simulationen gelöst werden, deshalb der Versuch meiner Vereinfachung des Problems.
Der Datensatz ist bereits strukturiert und welche Daten in die Analyse eingehen sollen auch bereits geklärt. Im Grunde suche ich jetzt nur nach einer Normierungsmöglichkeit um zu definieren, wie viele Spiele und Sätze welcher Spieler gewinnt.
Nachtrag: @bele: Vielen Dank für den Link das schaue ich mir mal genauer an, ich glaube das hilft mir sehr!
- FlyingGoshawk
- Grünschnabel
- Beiträge: 2
- Registriert: Do 10. Feb 2022, 13:56
- Danke gegeben: 0
- Danke bekommen: 0 mal in 0 Post
Re: Vorhersage eines Tennismatchs
![]() von bele » Fr 11. Feb 2022, 14:26
von bele » Fr 11. Feb 2022, 14:26
Hallo FlyingGoshawk,
wenn Du die Daten der anderen Spieler mit A und B und untereinander hast, dann kannst Du das viel eleganter lösen, indem Du die Spielgüte der anderen Spieler und von A und B mittels eines Bradley-Terry-Modells berechnest und dann kannst Du damit auch vorhersagen treffen, wie wahrscheinlich A gegen B gewinnt. Da kannst Du dann sogar noch weitere Kovariaten mit einbeziehen, ob z. B. auf Gras oder auf Sand gespielt wird, ob das Match durch zwei oder drei gewonnene Sätze definiert wird und so weiter.
Neben dem R package auf dessen Beschreibung ich im letzten Post verwiesen habe gab es gerade für besonders große Datensätze noch eines hier: https://cran.r-project.org/web/packages ... index.html das scheint aber derzeit nur noch auf github verfügbar unter https://github.com/EllaKaye/BradleyTerryScalable .
Aber auch, wenn Du das Bradley-Terry-Modell nicht vollständig übernimmst ist das Grundkonstrukt für Dich ideal, dass jedem Spieler eine Güte zugewiesen wird (mal heißt die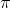 , mal
, mal 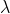 , mal
, mal 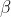 und dass man über die Differenz der Güte beider Spieler über eine logit-Transformation dann Siegchancen ausrechnen kann.
und dass man über die Differenz der Güte beider Spieler über eine logit-Transformation dann Siegchancen ausrechnen kann.
Viel Erfolg damit und melde Dich gerne nochmal, wenn es was geworden ist.
LG,
Bernhard
wenn Du die Daten der anderen Spieler mit A und B und untereinander hast, dann kannst Du das viel eleganter lösen, indem Du die Spielgüte der anderen Spieler und von A und B mittels eines Bradley-Terry-Modells berechnest und dann kannst Du damit auch vorhersagen treffen, wie wahrscheinlich A gegen B gewinnt. Da kannst Du dann sogar noch weitere Kovariaten mit einbeziehen, ob z. B. auf Gras oder auf Sand gespielt wird, ob das Match durch zwei oder drei gewonnene Sätze definiert wird und so weiter.
Neben dem R package auf dessen Beschreibung ich im letzten Post verwiesen habe gab es gerade für besonders große Datensätze noch eines hier: https://cran.r-project.org/web/packages ... index.html das scheint aber derzeit nur noch auf github verfügbar unter https://github.com/EllaKaye/BradleyTerryScalable .
Aber auch, wenn Du das Bradley-Terry-Modell nicht vollständig übernimmst ist das Grundkonstrukt für Dich ideal, dass jedem Spieler eine Güte zugewiesen wird (mal heißt die
Viel Erfolg damit und melde Dich gerne nochmal, wenn es was geworden ist.
LG,
Bernhard
----
`Oh, you can't help that,' said the Cat: `we're all mad here. I'm mad. You're mad.'
`How do you know I'm mad?' said Alice.
`You must be,' said the Cat, `or you wouldn't have come here.'
(Lewis Carol, Alice in Wonderland)
`Oh, you can't help that,' said the Cat: `we're all mad here. I'm mad. You're mad.'
`How do you know I'm mad?' said Alice.
`You must be,' said the Cat, `or you wouldn't have come here.'
(Lewis Carol, Alice in Wonderland)
- bele
- Schlaflos in Seattle
- Beiträge: 5976
- Registriert: Do 2. Jun 2011, 23:16
- Danke gegeben: 16
- Danke bekommen: 1412 mal in 1398 Posts
Thema bewerten: • 5 Beiträge
• Seite 1 von 1
Wer ist online?
Mitglieder in diesem Forum: 0 Mitglieder und 3 Gäste